
Written by: Ameerah
What is ETL
ETL stands for Extract, Transform, Load. It’s a process used to combine data from various sources into a single, consistent format suitable for analysis. Here’s a breakdown of the three steps involved:
- Extract: Data is retrieved from different sources, which can be structured databases, flat files, social media feeds, or any other data storage system.
- Transform: The extracted data undergoes various transformations to prepare it for analysis. This might involve cleaning inconsistencies, converting formats, removing duplicates, combining data from different sources, and applying calculations or business rules.
- Load: The transformed data is finally loaded into a target system, typically a data warehouse, data lake, or another analytical platform. This allows users to easily access and analyze the combined data for various purposes like reporting, trend identification, and decision-making.
ETL plays a crucial role in data management by providing a clean and unified foundation for data analysis. It helps organizations leverage data from multiple sources to gain insights, improve decision-making, and drive business value.
Why is ETL Important?
- Improved data quality: ETL helps clean and standardize data from various sources, ensuring accuracy and consistency for analysis.
- Enhanced data accessibility: ETL brings data together in a single location, making it easier to access and analyze for different departments within an organization.
- Informed decision-making: By providing high-quality, unified data, ETL empowers businesses to make informed decisions based on reliable insights.
- Regulatory compliance: ETL can help organizations meet data compliance requirements by ensuring data accuracy and traceability.
- Supports modern data strategies: ETL forms the foundation for working with large data volumes and enables integration with advanced analytics tools like machine learning.
How does ETL benefit business intelligence?
ETL plays a critical role in enabling effective business intelligence (BI) by providing the following benefits:
- Enhanced data quality: BI tools rely on clean and accurate data for reliable insights. ETL ensures data quality by cleaning inconsistencies, removing duplicates, and standardizing formats, leading to better and more trustworthy BI reports and analyses.
- Unified data view: BI often involves analyzing data from multiple sources, like sales, marketing, and customer service. ETL helps consolidate data into a single, unified view, eliminating the need for users to navigate different systems and simplifying the data analysis process.
- Improved efficiency and performance: By automating data extraction, transformation, and loading, ETL frees up valuable time and resources for analysts and allows them to focus on more strategic tasks like interpreting data and creating insights.
- Deeper data exploration: ETL prepares data for deeper analysis by applying business rules and calculations, enabling BI tools to uncover hidden patterns and relationships within the data and generate more valuable insights.
- Scalability for big data: ETL tools are designed to handle large volumes of data efficiently, making them suitable for organizations dealing with big data, a crucial aspect of modern BI practices.
In essence, ETL acts as the foundation for a strong BI system. By ensuring data quality, accessibility, and efficiency, ETL empowers businesses to leverage data effectively for better decision-making, improved performance, and gaining a competitive edge.
How has ETL Evolved?
ETL has undergone significant evolution over the years, adapting to the changing needs of data management and analysis. Here are some key aspects of its development:
- Shift from batch processing to real-time: Early ETL tools focused on batch processing, handling data in large chunks at specific intervals. However, with the rise of real-time data sources and the need for immediate insights, ETL has evolved to handle streaming data processing, allowing for continuous data integration and analysis.
- Emergence of ELT (Extract, Load, Transform): While traditional ETL involved transforming data before loading it into the target system, some modern approaches like ELT prioritize loading data first and then performing transformations later. This can be more advantageous for certain scenarios, especially when dealing with large datasets or when the specific transformations are not fully defined beforehand.
- Cloud-based solutions: The rise of cloud computing has led to the emergence of cloud-based ETL tools. These offer scalability, flexibility, and cost-effectiveness for organizations, allowing them to avoid managing on-premise infrastructure.
- Integration with artificial intelligence and machine learning: Advanced ETL tools are incorporating AI and machine learning capabilities to automate data cleaning, transformation, and anomaly detection, further improving data quality and efficiency.
- Focus on self-service and user-friendliness: Modern ETL tools are becoming more user-friendly and offer self-service capabilities, allowing even non-technical users to access and integrate data more easily.
Overall, the evolution of ETL reflects its continuous adaptation to the ever-growing volume, variety, and velocity of data. The focus is now on handling real-time data, utilizing cloud technologies, and leveraging AI/ML to streamline data integration and provide valuable insights for businesses.
How does ETL work?
ETL, or Extract, Transform, Load, is a process that integrates data from various sources into a single, unified format suitable for analysis. Here’s a breakdown of how it works:
- Extract:
- This stage involves identifying and retrieving data from various sources. These sources can be diverse, ranging from:
- Structured databases: Storing data in a pre-defined format like tables and columns.
- Flat files: Unstructured data stored in text files like CSV or Excel spreadsheets.
- Web APIs: Application programming interfaces providing data access from online platforms.
- Social media feeds: Data generated on social media platforms.
- Any other system capable of storing and providing data.
- Transform:
- The extracted data often needs cleaning and preparation before loading it into the target system. This stage involves various transformations, including:
- Cleaning & Standardizing: Removing inconsistencies, correcting errors, and ensuring data adheres to a consistent format (e.g., date format, units, etc.).
- Deduplication: Identifying and removing duplicate records to avoid skewed analysis.
- Joining & Combining: Merging data from different sources based on specific criteria to gain a comprehensive view.
- Calculations & Aggregations: Applying calculations or formulas to the data (e.g., averages, sums) or summarizing data into new formats.
- Deriving New Data: Creating new data points based on existing data and business rules.
- Load:
- In the final stage, the transformed data is loaded into a target system, typically:
- Data warehouse: A central repository designed for storing and analyzing historical data.
- Data lake: A large, centralized storage for raw or semi-structured data in its native format.
- Data mart: A subject-specific subset of a data warehouse, focusing on a particular business area or department.
- Other analytical platforms: Any system used for data analysis, such as business intelligence tools or machine learning models.
Overall, ETL acts as a bridge, allowing organizations to seamlessly integrate data from various sources into a unified format, enabling effective data analysis and decision-making.
What is Data Extraction?

Data extraction is the first step in the ETL (Extract, Transform, Load) process. It involves identifying and retrieving data from various sources and preparing it for further processing and analysis. Here’s a closer look at what data extraction entails:
Sources of data:
Data can be extracted from a wide range of sources, including:
- Structured databases: These store data in a pre-defined format, like tables and columns, making it easier to extract and process.
- Flat files: Unstructured data stored in text files like CSV or Excel spreadsheets requires more work to structure for further analysis.
- Web APIs: Application programming interfaces provide programmatic access to data from online platforms.
- Social media feeds: Data generated on social media platforms can be extracted for social listening or sentiment analysis.
- Sensor data: Data collected from various sensors, like temperature or pressure readings, can be valuable for monitoring and analysis.
- Log files: System logs often contain valuable information about user activity or system performance, which can be extracted for analysis.
Process of extraction:
The specific method of data extraction depends on the source and format of the data. Here are some common techniques:
- Using built-in tools: Many databases and software applications offer built-in tools for exporting data in different formats.
- Writing scripts: For complex data extraction tasks, scripting languages like Python or SQL can be used to automate the process.
- Web scraping: Techniques are used to extract data from websites, often for research or market analysis purposes. However, ethical considerations and website terms of service must be respected.
Importance of data extraction:
Data extraction plays a crucial role in enabling data analysis by:
- Providing access to valuable data: It allows you to gather information from diverse sources that would otherwise be inaccessible or difficult to combine.
- Preparing data for further processing: The extracted data can then be transformed and loaded into a format suitable for analysis, enabling you to gain insights from various data points.
Overall, data extraction is the foundation of any data-driven analysis process. By effectively retrieving data from various sources, you can unlock valuable insights and make informed decisions.
What is Data Transformation?

Data transformation is the second step in the ETL (Extract, Transform, Load) process. It involves manipulating and modifying extracted data to prepare it for analysis in a target system. Here’s a breakdown of what data transformation entails:
Purpose of data transformation:
- Improve data quality: This involves cleaning inconsistencies, correcting errors, and ensuring data adheres to a consistent format. This allows for accurate and reliable analysis.
- Structure data for analysis: Extracted data may be in various formats and structures. Transformation reshapes the data into a format suitable for the target system and analysis tools.
- Combine data from different sources: When data comes from diverse sources, it might need to be joined, merged, or aggregated to provide a comprehensive view.
- Derive new insights: Calculations, formulas, and business logic can be applied to create new data points or insights not explicitly present in the raw data.
Common data transformation techniques:
- Cleaning and standardization: This involves tasks like:
- Removing missing values, duplicates, and outliers.
- Standardizing data formats (e.g., date format, units, currency).
- Correcting spelling errors and inconsistencies.
- Data type conversion: Transforming data from one format to another (e.g., converting text to numbers, dates to different formats).
- Joining and combining: Merging data from different sources based on specific criteria to gain a holistic view. This can involve techniques like inner joins, outer joins, and unions.
- Aggregation: Summarizing data by applying functions like sum, average, count, or minimum/maximum values. This provides a concise overview of larger datasets.
- Deriving new data: Creating new data points based on existing data and business rules. This might involve calculations, formulas, or applying conditional logic.
Benefits of data transformation:
- Improved data quality leads to reliable insights.
- Structured data allows for efficient and accurate analysis.
- Combined data from various sources provides a comprehensive view.
- Derived data unlocks new insights and understanding.
Overall, data transformation plays a critical role in turning raw data into usable information. By applying appropriate transformations, you can prepare your data for analysis and extract valuable insights to inform decision-making.
What is Data Loading?

Data loading is the final step in the ETL (Extract, Transform, Load) process. It involves transferring and importing the transformed data from the staging area into a target system where it can be stored and analyzed. Here’s a closer look at what data loading entails:
Destination of loaded data:
The target system for data loading can vary depending on the organization’s needs and analysis goals. Common destinations include:
- Data warehouse: A central repository designed for storing and analyzing historical data, often used for long-term trends and reporting.
- Data lake: A large, centralized storage for raw or semi-structured data in its native format, enabling exploration of diverse data sources.
- Data mart: A subject-specific subset of a data warehouse, focusing on a particular business area or department and supporting specific analysis needs.
- Analytical platforms: Other systems used for data analysis, such as business intelligence tools, machine learning models, or visualization tools.
Process of data loading:
The specific method of data loading depends on the target system and the format of the transformed data. Here are some common techniques:
- Bulk loading: Efficiently transferring large amounts of data into the target system at once.
- Streaming data loading: Real-time transfer of data in small chunks, suitable for continuous data analysis.
- Using specialized tools: Many target systems offer built-in tools or APIs for importing data in specific formats.
- Custom scripts: In specific scenarios, custom programming scripts might be used to handle complex data-loading tasks.
Considerations for data loading:
- Data integrity: Ensuring data is loaded accurately and consistently without errors or duplicates is crucial.
- Performance: The loading process should be efficient to avoid impacting the performance of the target system.
- Security: Implementing proper security measures to protect sensitive data during and after loading is essential.
Importance of data loading:
Data loading forms the final stage of delivering clean and transformed data to its designated location, enabling further analysis and insights. It acts as the bridge between data preparation and its potential value for decision-making.
Overall, data loading serves as the final step in the ETL pipeline, completing the journey of data from various sources to its usable form for analysis and driving valuable insights.
What is ELT?
ELT, which stands for Extract, Load, Transform, is a variation of the traditional ETL (Extract, Transform, Load) data processing method. It shares the same goal of integrating data from various sources into a single location for analysis, but differs in the order of the steps.
Here’s a breakdown of the key differences:
Traditional ETL:
- Extract: Data is retrieved from different sources.
- Transform: The extracted data is cleaned, standardized, and transformed before loading.
- Load: The transformed data is loaded into the target system (data warehouse, data lake, etc.).
ELT:
- Extract: Data is retrieved from different sources.
- Load: The raw, un-transformed data is directly loaded into the target system.
- Transform: The data is then transformed within the target system.
Advantages of ELT:
- Faster loading: By skipping initial transformation, ELT can load data into the target system quicker, especially for large datasets.
- Flexibility: Transformations can be adapted and refined later based on specific analysis needs, offering more flexibility.
- Scalability: ELT can handle large, complex data volumes more efficiently as the target system typically has greater processing power for transformations.
Disadvantages of ELT:
- Increased complexity: Transforming data within the target system can be more complex and require specialized skills.
- Data quality concerns: Loading untransformed data may lead to quality issues if not carefully managed, potentially impacting analysis.
- Performance impact: Transformations within the target system can potentially impact its performance, especially for complex data manipulation.
What is ETL and ELT – Some Key Differences
| Feature | ETL | ELT |
|---|---|---|
| Transformation order | Before loading | After loading |
| Target system processing | Limited transformation capabilities | Often has built-in transformation capabilities |
| Complexity of transformations | Can handle complex transformations before loading | May have limitations on transformation complexity within the target system |
| Data quality control | Easier to control data quality before loading | Requires robust data quality checks within the target system |
| Performance | May be slower due to complex preprocessing | Can be faster as raw data is loaded first |
| Scalability | Can be less scalable for very large datasets | May be more scalable for large datasets due to leveraging target system’s processing power |
Choosing between ETL and ELT:
The choice between ETL and ELT depends on various factors, including:
- Data size and complexity: ELT might be more suitable for handling large datasets where speed is crucial.
- Transformation complexity: If transformations are straightforward and well-defined, ETL might be easier to manage.
- Target system capabilities: The target system’s ability to handle transformations within its environment needs to be considered.
- Technical expertise: Implementing and managing ELT may require specialized skills in data warehousing and transformation techniques.
Ultimately, both ETL and ELT serve the purpose of data integration for analysis. Choosing the best approach depends on your specific needs, priorities, and technical capabilities.
What is Data Virtualization?

Data virtualization is an approach to managing and accessing data that allows users and applications to retrieve and manipulate data from diverse sources without requiring technical knowledge about the underlying data storage or formats. It essentially creates a single, virtual view of data that hides the complexities of the physical data infrastructure.
Here’s a deeper look into data virtualization:
Key features and benefits:
- Single view of data: Data virtualization presents a unified view of data from various sources, including databases, data warehouses, cloud storage, and applications, simplifying data access and analysis.
- Improved data accessibility: Users can seamlessly access and work with data regardless of its location or format, increasing data utilization and reducing reliance on IT specialists.
- Reduced complexity: Data virtualization eliminates the need for complex data integration projects like ETL (Extract, Transform, Load) processes, minimizing development and maintenance effort.
- Real-time access: In certain implementations, data virtualization can provide real-time access to data, enabling up-to-date insights and quicker decision-making.
- Improved data governance and security: Data virtualization can enforce centralized security policies and access controls across all data sources, enhancing data security and compliance.
How it works:
- Data virtualization layer: A software layer sits between users and applications and the actual data sources. This layer acts as a virtual data warehouse, understanding the data structures and formats from various sources.
- Data mapping: The data virtualization layer maps the physical data structures from each source to a common logical data model, making it easier for users and applications to understand and interact with the data.
- Query translation: When a user or application submits a query, the data virtualization layer translates it into the specific language understood by the underlying data source. It then retrieves the data, transforms it if necessary based on the mapping, and presents the results as if they came from a single source.
Use cases of data virtualization:
- Data warehousing and BI reporting: Provides a unified view of data for various analytical tools and dashboards, streamlining reporting and analysis processes.
- Application development: Enables rapid integration of data from different sources into applications, reducing development time and complexity.
- Data governance and compliance: Facilitates centralized control and access management across diverse data sources, ensuring data security and adherence to regulations.
- Master data management: Creates a single, consistent view of key business entities across various systems, improving data accuracy and consistency.
Overall, data virtualization simplifies data management and access, offering a valuable approach for organizations seeking to improve data utilization, streamline data integration, and gain insights from diverse data sources.
ETL skills
ETL skills can be categorized into technical skills and non-technical skills:
Technical Skills:
- SQL: This is fundamental as most ETL tools rely heavily on SQL for data extraction, transformation, and loading. Expertise in writing queries, joining tables, and data manipulation is crucial.
- Scripting languages: Familiarity with scripting languages like Python, Bash, Perl enhances your ability to automate tasks, write custom scripts for complex transformations, and interact with different data sources and systems.
- ETL tools: Knowledge of popular ETL tools like Informatica PowerCenter, IBM DataStage, Talend Open Studio is valuable. These tools offer user-friendly interfaces and functionalities for building data pipelines.
- Data warehousing concepts: Understanding data warehouse architecture, star schema design, and data modeling principles is beneficial for working with data warehouses as target systems.
- Data quality concepts: Familiarity with data cleaning techniques, data profiling, and data validation methods is essential to ensure the quality and accuracy of data throughout the ETL process.
Non-Technical Skills:
- Problem-solving and analytical skills: The ability to analyze data requirements, identify potential issues, and troubleshoot errors during the ETL process is crucial.
- Communication skills: Effective communication with stakeholders, including business analysts and data users, is essential to understand their needs and ensure the ETL process delivers the desired results.
- Organizational skills: Strong organization is key to managing complex ETL projects, keeping track of data sources, transformations, and ensuring timely delivery.
- Attention to detail: Careful attention to detail is vital to avoid errors in data extraction, transformation, and loading, ensuring data integrity and quality.
- Adaptability: The ability to adapt to changing requirements, new data sources, and emerging technologies is essential in the ever-evolving world of data management.
Additional skills:
- Cloud computing: Familiarity with cloud platforms like AWS, Azure, Google Cloud Platform is increasingly relevant as more organizations leverage cloud-based ETL solutions.
- Big data technologies: Knowledge of big data frameworks like Hadoop, Spark can be valuable for handling large and complex datasets.
- Data visualization: Understanding data visualization principles can help you present transformed data in a clear and meaningful way for analysis.
By developing both technical and non-technical skills, you can become a well-rounded ETL professional capable of designing, implementing, and managing efficient data integration pipelines to support data-driven decision-making.
ETL Requirements
ETL requirements can be broadly categorized into functional and technical aspects. Here’s a breakdown of both categories:
Functional Requirements:
- Data source connectivity: The ETL solution should be able to connect to various data sources, including databases (structured and semi-structured), flat files, APIs, web services, and cloud storage platforms.
- Data extraction capabilities: The ability to effectively extract data from diverse sources, considering aspects like authentication, scheduling, and handling errors, is crucial.
- Data transformation capabilities: The solution should support various transformations like cleaning, filtering, merging, joining, aggregation, and derivation of new data points based on business rules.
- Data loading capabilities: The ETL tool should efficiently load transformed data into the target system, whether a data warehouse, data lake, data mart, or other analytical platform.
- Data quality management: The ability to ensure data accuracy, consistency, and completeness throughout the ETL process, including data profiling, validation, and error handling, is essential.
- Reporting and monitoring: The solution should provide reports and dashboards to monitor the ETL process, track data lineage (traceability of data movement), and identify any potential issues for troubleshooting.
- Security and compliance: The ETL tool should adhere to appropriate security protocols and comply with relevant data privacy regulations to protect sensitive data during processing.
Technical Requirements:
- Scalability: The solution should be able to handle increasing data volumes and complexities as your data needs evolve.
- Performance: The ETL process needs to be efficient and avoid impacting the performance of source and target systems.
- Usability: The user interface should be intuitive and user-friendly, allowing both technical and non-technical users to interact with the ETL process effectively.
- Integration capabilities: The ability to integrate with other data management tools, business intelligence platforms, and cloud services can be beneficial for a holistic data ecosystem.
- Interoperability: The ETL tool should be compatible with diverse data formats, operating systems, and hardware platforms.
- Cost-effectiveness: Choosing a cost-effective solution that aligns with your budget and licensing requirements is important.
Additional Considerations:
- Specific industry regulations: Depending on your industry, there might be specific data privacy and security regulations that the ETL tool needs to comply with.
- Existing IT infrastructure: Consider the compatibility of the ETL solution with your existing technology stack and data management infrastructure.
- Future needs: Plan for potential future growth by choosing an ETL tool that can scale to meet your evolving data needs.
By carefully considering both functional and technical requirements, you can select an ETL solution that effectively addresses your specific data integration needs and empowers your organization to leverage data effectively for informed decision-making.
ETL Architecture Diagram
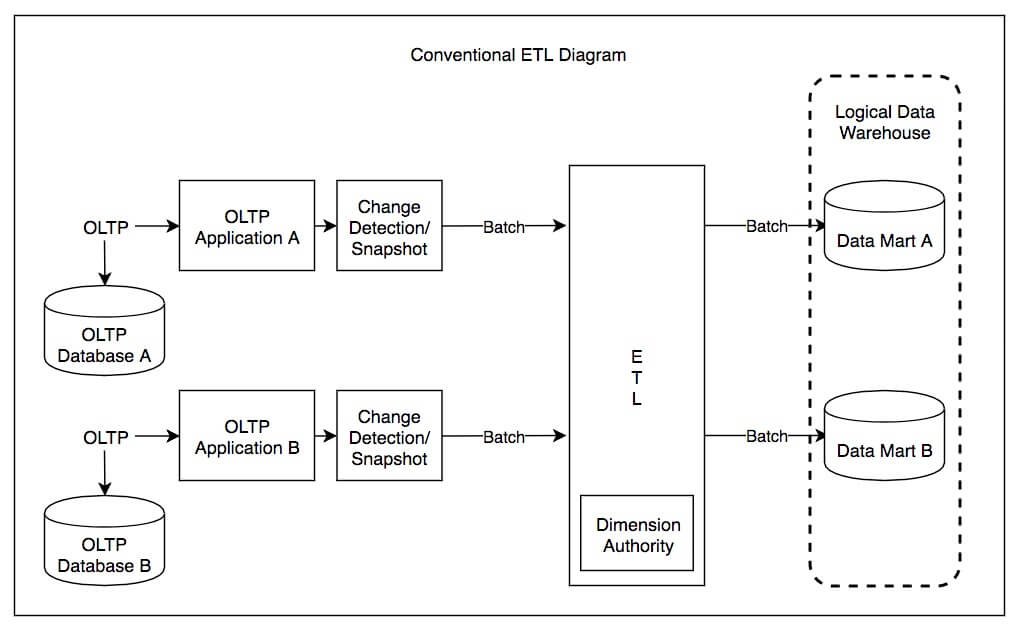
Components:
- Data Sources: The variety of sources represented in the diagram highlights the ability to extract data from a wide range:
- OLTP Applications (A & B): These represent Operational Line-Of-Trade Processing systems, typically transactional databases that handle the day-to-day operations of a business.
- OLTP Databases (A & B): Separate databases, potentially structured differently, that also feed into the ETL process.
- Change Detection/Snapshot: Mechanisms used to specifically identify and capture updates or historical data in the source systems.
- Staging Area: While not explicitly labeled as a staging area, the central section where all the arrows converge likely represents a temporary data storage location. Data from various sources may undergo initial cleansing and preparation here before further transformation.
- ETL Engine: The primary ETL work seems to be happening in the center. However, some transformations might be occurring within the data marts, making this a hybrid ETL/ELT approach. This central section is primarily responsible for applying the necessary transformations.
- Transformation Logic: While not directly visible in the diagram, the specific transformations would be defined and implemented within the ETL Engine and possibly the data marts, consisting of:
- Cleaning & Standardizing
- Joining & Combining
- Calculations & Aggregations
- Deriving New Data
- Target Systems: The diagram depicts two data marts (Data Mart A & B) as the final destinations, serving as subject-specific repositories for analysis. Additionally, “Dimension Authority” likely represents a central source of dimension data (reference data) used to enrich the data marts.
Data Flow:
- Extract: Data is extracted from both OLTP Applications and Databases, likely using Change Detection/Snapshot mechanisms to facilitate efficient extraction of updates or historical records.
- Transform (Initial): Data likely undergoes some initial cleaning, preparation, and potentially some initial transformations in the staging area (the center of the diagram).
- Load: Data is loaded into specific Data Marts (A & B)
- Transform (Final): Further transformations might occur within the Data Marts to tailor data for specific analysis requirements.
- Dimension Data: The data marts likely utilize reference data from the “Dimension Authority” to enrich the integrated data for better analysis.
Overall Observations:
- Hybrid Approach: The diagram seems to represent a hybrid ETL/ELT approach since some transformations are likely happening before and potentially even after loading into the data marts.
- Focus on Data Marts: The presence of multiple data marts highlights a decentralized approach to data presentation, focusing on subject-specific data repositories for particular business units.
- Importance of Reference Data: The “Dimension Authority” acts as a master source of reference data, crucial for ensuring data consistency and enabling more insightful analysis.
ETL synonyms
While there aren’t any widely used synonyms for “ETL” itself, there are related terms and phrases that describe similar concepts or aspects of the ETL process:
- Data Integration: This is a broader term encompassing various strategies and techniques for combining data from diverse sources into a unified format for analysis. ETL is considered a specific type of data integration method.
- Data Warehousing: Although closely related, data warehousing focuses on the design, construction, and management of a central repository (data warehouse) for storing and analyzing historical data. ETL is one of the key processes used to populate and maintain data warehouses.
- Data Transformation: This refers specifically to the manipulation and modification of extracted data to prepare it for analysis. It forms a crucial aspect of the ETL process.
- Data Migration: While data migration involves moving data from one system to another, it’s typically a one-time activity, whereas ETL is an ongoing process for continuous data integration and preparation.
- Data Extraction & Transformation (E&T): This term emphasizes the combination of extraction and transformation stages, potentially skipping the “load” phase in an ELT approach.
- Data Processing: This is a broad term encompassing various operations performed on data, including extraction, transformation, loading, cleaning, and analysis. ETL is a specific type of data processing focused on data integration for analytical purposes.
Free ETL Tools
Several free and open-source ETL tools are available, each with its strengths and weaknesses. Here are a few popular options to consider:
- Cloud-based: Offers a user-friendly interface and pre-built connectors for various data sources and destinations.
- Real-time support: Enables real-time data pipelines for continuous data integration.
- Open-source: Freely available for download and customization.
- Scalable and flexible: Can handle large data volumes and complex workflows.
- Java-based: Requires some programming knowledge for configuration and customization.
- Open-source: Freely available for download and customization.
- Drag-and-drop interface: Offers a user-friendly interface for building data pipelines visually.
- Wide range of connectors: Supports a variety of data sources and destinations.
- Freemium model: The free version has limitations on data volume and features.
- Cloud-based: Offers a freemium plan with limited features.
- Automated data pipelines: Automates data extraction, transformation, and loading tasks.
- User-friendly interface: Provides a visual interface for data pipeline creation.
Kettle (Pentaho Data Integration)
- Open-source: Freely available for download and customization.
- Java-based: Requires some programming knowledge for configuration and customization.
- Flexible and powerful: Offers a wide range of features and functionalities.
Choosing the right free ETL tool depends on your specific needs and technical expertise. Consider factors like:
- Data volume and complexity: Choose a tool that can handle your data volume and complexity requirements.
- Ease of use: If you’re new to ETL, a user-friendly interface is essential.
- Supported data sources and destinations: Ensure the tool supports the data sources and destinations you need to connect to.
- Scalability: Consider your future data growth and choose a tool that can scale accordingly.
Remember, these are just a few examples, and many other free and open-source ETL tools are available. It’s recommended to research and evaluate different options to find the best fit for your specific needs.
Conclusion – What is ETL
ETL (Extract, Transform, Load) plays a critical role in bridging the gap between diverse data sources and meaningful analysis. It facilitates the integration of data from various sources, cleanses and prepares it for analysis, and loads it into a target system where it can be explored and utilized to gain valuable insights.
Key takeaways about What is ETL:
- Importance: ETL is essential for organizations working with data from multiple sources, enabling them to consolidate, integrate, and analyze their data effectively.
- Benefits: It offers several benefits, including:
- Improved data quality and consistency
- Increased accessibility and utilization of data
- Enhanced data-driven decision-making
- Simplified reporting and analysis processes
- Evolution: ETL has evolved over time, adapting to the ever-growing volume, variety, and velocity of data. Modern approaches like ELT (Extract, Load, Transform) and cloud-based solutions are gaining popularity.
- Skills and tools: Developing technical and non-technical skills relevant to ETL, combined with choosing the appropriate tools and understanding the requirements of your specific data management needs, are crucial for successful ETL implementation.
Overall, ETL remains a fundamental process for organizations seeking to leverage the power of data and gain valuable insights to inform their strategies and operations. As data continues to grow and evolve, the importance of effective ETL practices will only become more significant in the future.























